

Can Your PC Run OpenAI's New GPT-OSS Large Language Models?
These new AI models from the maker of ChatGPT are available for anyone to download and run, if you have enough RAM and processing power.How-To
On August 5, 2025, OpenAI returned to the world of open-weights large language models, and it did so in grand fashion. Though six years have passed since the company’s last open model, OpenAI’s popularity guaranteed that hardware vendors across the globe were eager to jump on board. Qualcomm, AMD, Nvidia, and Microsoft immediately announced support.
What is OpenAI’s new GPT-OSS-20b model?
OpenAI’s GPT-OSS is currently available in two flavors: GPT-OSS-20b and GPT-OSS-120b. The latter requires a GPU with at least 60GB of memory, though, so it’s out of the question for most consumer hardware.
That leaves GPT-OSS-20b. It’s a large language model with, as the name implies, 20 billion parameters. While that’s fairly small as large language models go, it’s not tiny.
To mitigate that, GPT-OSS-20b uses a mixture-of-expert architecture that only requires use of some parameters to generate a response to a prompt. It also uses quantization, which reduces each parameter to 4.25 bits, compressing its size. GPT-OSS-20b is a 12.8GB download.
GPT-OSS-20b is also a reasoning model that uses chain-of-thought steps to better solve complex problems. That should improve the quality of its result, though it can also make a model slower to reply.
To compensate for that, users can select from low, medium, and high reasoning effort. I found the gap between medium and high was far larger than between low and medium. My attempts to run high reasoning effort often didn’t complete unless I bumped up the context window, which in turn increased memory demands.
OpenAI’s benchmarks claim that GPT-OSS-20b can match or beat o3-mini in some tests, like the Codeforces Competition Code benchmark.
How I tested GPT-OSS-20b
OpenAI’s model card says that GPT-OSS-20b can run on systems with as little as 16GB of RAM (or 16GB of VRAM, if your PC has a GPU). That has led to widespread claims that GPT-OSS-20b is optimized for laptops.
Photo: Matthew Smith
I decided to put that to the test. To do so, I ran GPT-OSS-20b through several prompts on four different systems.
-
Microsoft Surface Laptop 13.8 with Snapdragon X Elite, 32GB RAM
-
Custom-built desktop with AMD Ryzen 5950X, AMD Radeon 7800 XT 16GB, 32GB RAM
The links above will direct you to a Google Sheet where the prompts and replies are available. I used LM Studio for my testing.
Prompt 1: Writing an email
Let’s start with something simple: a short email. This is a writing test that doesn’t require much reasoning effort and results in a short reply, with a total token count (for prompt and reply) often around 500 tokens. I ran this prompt with low reasoning effort.
So, how did our test systems handle it?
| Device/System | First Token | Tokens Per Second |
|---|---|---|
| Apple Mac Mini M4 16GB | 7.34 | 17.84 |
| Apple MacBook Air 15 M4 24GB | 0.71 | 28.89 |
| Microsoft Surface Laptop 13.8 32GB | 0.05 | 26.24 |
| Custom desktop: AMD 5950X/7800XT 32G RAM/16GB VRAM | 0.82 | 32.5 |
The Apple Mac Mini with M4 and 16GB of memory came in last, and by a large margin. This conflicts with claims that 16GB of memory is sufficient. That may be true, but only if that 16GB is dedicated graphics memory. A system with 16GB of total memory struggles because, of course, some of that memory must be dedicated to other tasks.
The Microsoft Surface Laptop 13.8 and Apple MacBook Air 15 were considerably quicker in this task, thanks to their larger available memory. They provided a much quicker time to first token (TTFT), which means they feel more responsive, and produced roughly 60 to 80% more tokens per second. These machines wrote the short email in less than 15 seconds.
The desktop with an AMD Radeon 7800XT GPU was quicker, but not by much, and showed no obvious advantage in time to first token. However, as we’ll soon see, that pattern does not hold in longer-duration tasks.
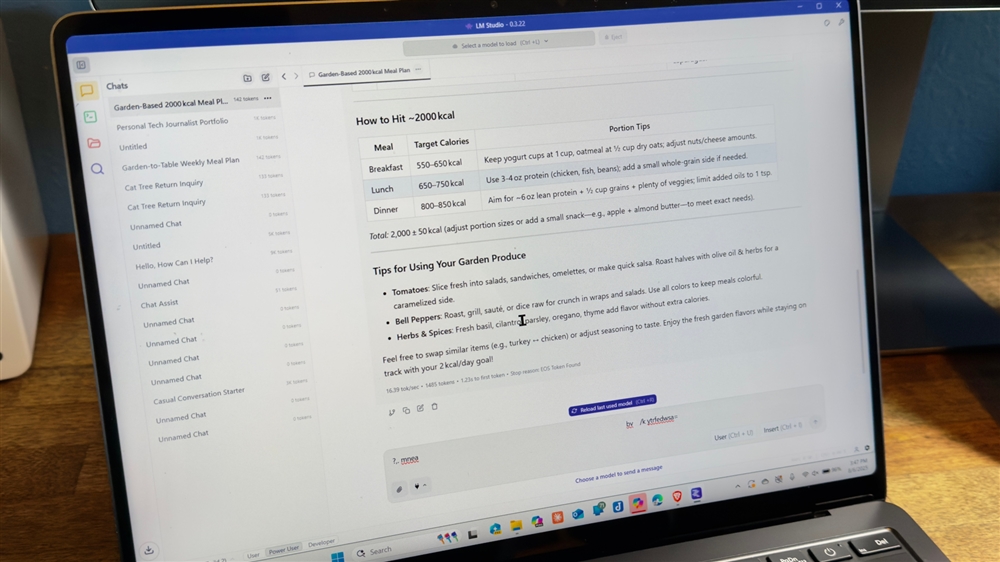
Prompt 2: Creating a meal plan
The second prompt I tried is a task that better leans on the advantages of a reasoning model. I asked the model to create a one-week meal plan that would help me use tomatoes and peppers ripening in my garden, and would target a caloric intake around 2,000 calories per day. I ran this prompt with medium reasoning effort.
| Device/System | First Token | Tokens Per Second |
|---|---|---|
| Apple Mac Mini M4 16GB | 8.58 | 13.74 |
| Apple MacBook Air 15 M4 24GB | 0.75 | 14.34 |
| Microsoft Surface Laptop 13.8 32GB | 1.23 | 14.35 |
| Custom desktop: AMD 5950X/7800XT 32G RAM/16GB VRAM | 0.22 | 30.43 |
The results produced by this task differ quite a bit from the first.
The Apple Mac Mini is still the slowest, and suffers from a particularly slow time to first token. It provides no response at all for 8.5 seconds.
Once the response gets rolling, however, the Mac Mini, MacBook Air, and Surface Laptop all produce a similar number of tokens per second. In addition to that, all three produce significantly fewer tokens per second than in the first task.
That indicates performance throttling, or a performance bottleneck, is becoming a factor. Performance monitoring in Task Manager and Activity Monitor backed that up. All three systems were running full-tilt.
The desktop, on the other hand, enjoyed a big performance lead as it continued to produce over 30 tokens per second. That makes it twice as quick as the laptops used for comparison.
My takeaway? Laptops with NPUs aren't as optimized for this as a GPU, even when compared to one that isn't great on paper for AI tasks, such as the Radeon RX 7800 XT in my desktop.
Prompt 3: Creating a website
My final and most complex prompt tasked GPT-OSS-20b with re-creating my personal portfolio website. It’s a simple site with all code in one HTML document, but it does include some Javascript. I provided an elaborate prompt, not only so that the website included the same copy as the website I already have, but also so that all images and links still worked. I ran this prompt with medium reasoning effort.
| Device/System | First Token | Tokens Per Second |
|---|---|---|
| Apple Mac Mini M4 16GB | 21.8 | 12.86 |
| Apple MacBook Air 15 M4 24GB | 4.35 | 13.00 |
| Microsoft Surface Laptop 13.8 32GB | 0.2 | 12.84 |
| Custom desktop: AMD 5950X/7800XT 32G RAM/16GB VRAM | 1.45 | 28.88 |
The general trend of the performance results did not change in this test. The Mac Mini and the laptops produced similar tokens per second, while the desktop more than doubled their performance.
But, wow, look at that time to first token on the Apple Mac Mini M4. It’s clearly struggling to stuff the prompt into the model, which results in a nearly 22-second wait to see anything happen at all.
Does GPT-OSS-20b produce quality results?
Judging the quality of a model is difficult, which is why some very smart people devote their entire careers to building complicated AI benchmarks that span hundreds of queries.
My first impression, however, is that GPT-OSS-20b feels solid. I was particularly happy with how GPT-OSS-20b handled the website prompt. I created my website late last year with the help of Claude 3.5, but it wasn’t one-and-done. The initial results from GPT-OSS-20b look better than what Claude 3.5 spat out on its first try.
Image: Matthew Smith
Of course, models have advanced since, and GPT-OSS-20b won’t match the latest cutting-edge models from OpenAI, Anthropic, Google, DeepSeek, Alibaba, and other top contenders. But I do think GPT-OSS-20b is useful for tasks like writing short emails, editing documents, generating recipes, and coding small scripts and programs, especially if you want to keep your AI tasks running on your local machine instead of a cloud service (an increasingly important distinction for businesses and individuals concerned with data security).
What you need really need to handle GPT-OSS-20b
OpenAI’s model card states that GPT-OSS-20b can run on systems with as little as 16GB of memory, but that’s pushing it. It assumes 16GB of memory totally dedicated to the LLM. But if you only have 16GB of total system memory, that’s not enough.
You’ll need 24GB or 32GB of RAM to see passable performance. Alternatively, a GPU with 16GB VRAM (or more) can step in to do the heavy lifting, as the GPU’s entire VRAM can be dedicated to the LLMs.
However, the tests show RAM isn’t the only bottleneck. You also need a healthy amount of AI inference compute available. This once again calls for a powerful GPU. Laptops with an NPU and less powerful GPUs, like the MacBook Air and Surface Laptop, can sorta get by, but are notably slower than even a mid-range GPU.
That means you’ll need a powerful PC or Mac for the best results. GPT-OSS-20b is very efficient in terms of model quality relative to the model’s size, and it does raise the bar on what LLMs can achieve on consumer hardware. However, we’re still a long way from a world where an entry-level consumer PC can handle even modestly sized large language models.




Recent Posts




Everything You Need to Know About WiFi 7
From dual-band basics to multi-gigabit speeds, WiFi has come a long way, and WiFi 7 is the most transformative leap yet. Whether you're powering a smart home, streaming in 8K, gaming in real time, or working from the cloud, this new standard is designed for how we use the internet today.
Continue Reading